d_model = 40
a = torch.zeros((1, d_model, 16, 500))
l = PositionalEncoding2D(d_model=d_model, freq_factor=1_000)
l_pos = l(a)
print(l_pos.shape)torch.Size([1, 40, 16, 500])
def DownBlock2D(
in_ch, out_ch, kernel_size:int=2, stride:int=2, padding:int=0, use_conv:bool=True
):
A 2d down scale block.
def UpBlock2D(
in_ch, out_ch, kernel_size:int=2, stride:int=2, padding:int=0, use_conv:bool=True
):
A 2d up scale block.
def ResBlock2D(
in_ch, out_ch, kernel_size, skip:bool=True, num_groups:int=32
):
A 2d residual block.
def ResBlock2DConditional(
in_ch, out_ch, t_emb_size, kernel_size, skip:bool=True
):
A 2d residual block with input of a time-step \(t\) embedding.
def FeedForward(
in_ch, out_ch, inner_mult:int=1
):
A small dense feed-forward network as used in transformers.
Create sinusoidal position embeddings, same as those from the transformer:
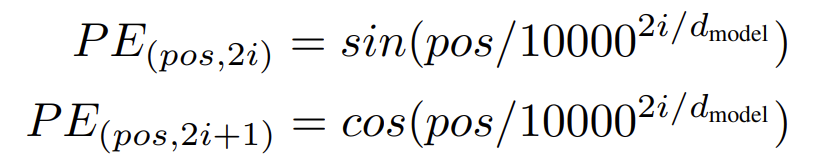
def PositionalEncoding(
d_model:int, dropout:float=0.0, max_len:int=5000, freq_factor:float=10000.0
):
An absolute pos encoding layer.
def TimeEmbedding(
d_model:int, dropout:float=0.0, max_len:int=5000, freq_factor:float=10000.0
):
A time embedding layer
def PositionalEncodingTransposed(
d_model:int, dropout:float=0.0, max_len:int=5000, freq_factor:float=10000.0
):
An absolute pos encoding layer.
def PositionalEncoding2D(
d_model:int, dropout:float=0.0, max_len:int=5000, freq_factor:float=10000.0
):
A 2D absolute pos encoding layer.
d_model = 40
a = torch.zeros((1, d_model, 16, 500))
l = PositionalEncoding2D(d_model=d_model, freq_factor=1_000)
l_pos = l(a)
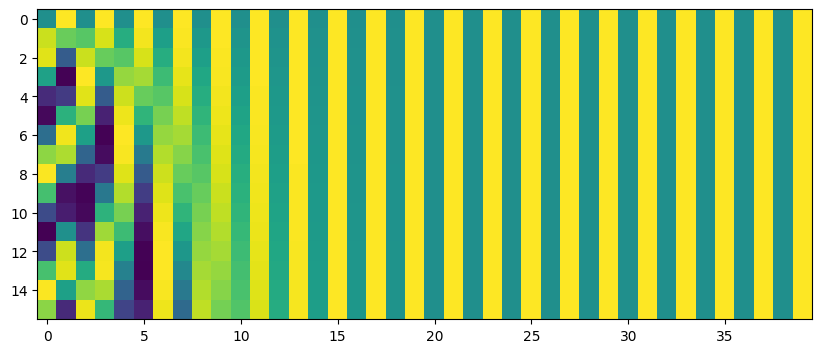
print(l_pos.shape)torch.Size([1, 40, 16, 500])#plot for a fixed space position, and show the vector depending on time position
x_pos = 0
plt.figure(figsize=(10, 5))
plt.imshow(l_pos[0, :, x_pos])
plt.show()
#plot for a fixed time position, and show the vector depending on space position
t_pos = 0
plt.figure(figsize=(10, 5))
plt.imshow(l_pos[0, :, :, t_pos].T)
plt.show()